Internals¶
The internals chapter describes and analyses most of the inner workings of Borg.
Borg uses a low-level, key-value store, the Repository, and implements a more complex data structure on top of it, which is made up of the manifest, archives, items and data Chunks.
Each repository can hold multiple archives, which represent individual backups that contain a full archive of the files specified when the backup was performed.
Deduplication is performed globally across all data in the repository (multiple backups and even multiple hosts), both on data and file metadata, using Chunks created by the chunker using the Buzhash algorithm (“buzhash” chunker) or a simpler fixed blocksize algorithm (“fixed” chunker).
To actually perform the repository-wide deduplication, a hash of each chunk is checked against the chunks cache, which is a hash-table of all chunks that already exist.
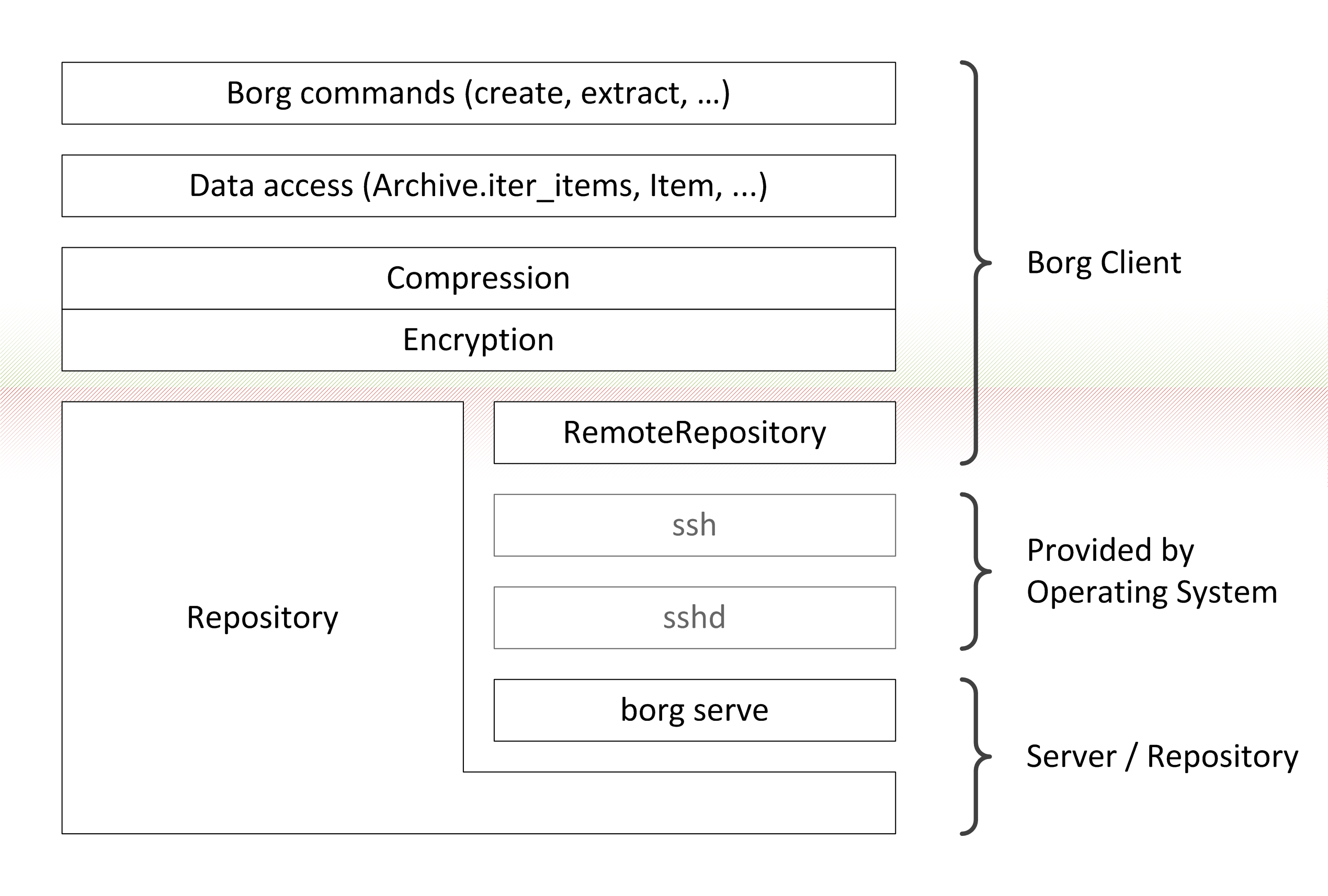
Layers in Borg. On the very top commands are implemented, using a data access layer provided by the Archive and Item classes. The “key” object provides both compression and authenticated encryption used by the data access layer. The “key” object represents the sole trust boundary in Borg. The lowest layer is the repository, either accessed directly (Repository) or remotely (RemoteRepository).¶